During process of learning MongoDB, aggregation pipeline was probably the biggest surprises I had.
At present moment it's presented as an alternative for Map/Reduce queries.
In my opinion the simplicity and flexibility, makes it a great tool for general analysis of datasets.
Single Purpose Aggregation Operations
If we want to perform simple count, group elements or get unique values for field, MongoDB provides build in methods for that. There is no need to use Map/Reduce or Aggregation Pipline for this trivial queries.
> db.books.distinct("author")
> // uniqe author entires in books collection
>
> db.books.count({author: "Stephen King"})
> // count how many books were writen by S. King
Group operation is a little bit more complicated and need more detailed example:
> db.books.insert({ title: "The Mist", author: "Stephen King", amount: 3 })
> db.books.insert({ title: "The Green Mile", author: "Stephen King", amount: 1 })
> db.books.insert({ title: "Under the Dome", author: "Stephen King", amount: 0 })
> db.books.insert({ title: "The Hobbit", author: "J.R.R. Tolkien", amount: 3 })
> db.books.insert({ title: "1984", author: "George Orwell", amount: 19 })
> // provide example data
>
> db.books.group( {
key: { author: 1 },
cond: { amount: { $gt: 0 } },
reduce: function(current, result) { result.count += current.amount },
initial: { count: 0 }
} )
->
{
"0" : {
"author" : "Stephen King",
"count" : 4
},
"1" : {
"author" : "J.R.R. Tolkien",
"count" : 3
},
"2" : {
"author" : "George Orwell",
"count" : 19
}
}
> // 'key' and 'reduce' are required fields
> // 'key' specifies which fields should be used to split collection into groups
> // 'reduce' provides function performed on each group of elements
Group operation has one serious weakness,
it will fail if output exceed 16 Mb.
If your group operation could meet that limit,
you should use aggregation framework.
Aggregation Pipeline
We have given task: In library, we need to check which author has the biggest amount of specific books title.
Filter out all title with zero amount.
> db.coding_books.insert({ author_id: 1, title: "Foo", author: "Bill", amount: 12 })
> db.coding_books.insert({ author_id: 1, title: "Bar", author: "Bill", amount: 9 })
> db.coding_books.insert({ author_id: 2, title: "FooBar", author: "Tom", amount: 1 })
> db.coding_books.insert({ author_id: 3, title: "Nope", author: "root", amount: 0 })
> // provide new data
First stage is filtering out all unwonted entries. To do so, we need to use match - aggregation operator.
There is variety of aggregation operators, $match, $group, $sort, $limit are some of the most basic.
> db.coding_books.aggregate({ $match: { amount: { $gt: 0 } } })
{
"result" : [
{
"_id" : ObjectId("537100dca6b4a6ebc08972c2"),
"author_id" : 1,
"title" : "Foo",
"author" : "Bill",
"amount" : 12
},
{
"_id" : ObjectId("537100dca6b4a6ebc08972c3"),
"author_id" : 1,
"title" : "Bar",
"author" : "Bill",
"amount" : 9
},
{
"_id" : ObjectId("537100dca6b4a6ebc08972c4"),
"author_id" : 1,
"title" : "FooBar",
"author" : "Tom",
"amount" : 1
}
],
"ok" : 1
}
Done, now group operator will calculate biggest amount of book for each author.
> db.coding_books.aggregate(
{ $match: { amount: { $gt: 0 } } },
{ $group: { _id: "$author_id", max: { $max: "$amount" } } }
)
{
"result" : [
{
"_id" : 2,
"max" : 1
},
{
"_id" : 1,
"max" : 12
}
],
"ok" : 1
}
As always, visualization should be helpful with understanding the flow.
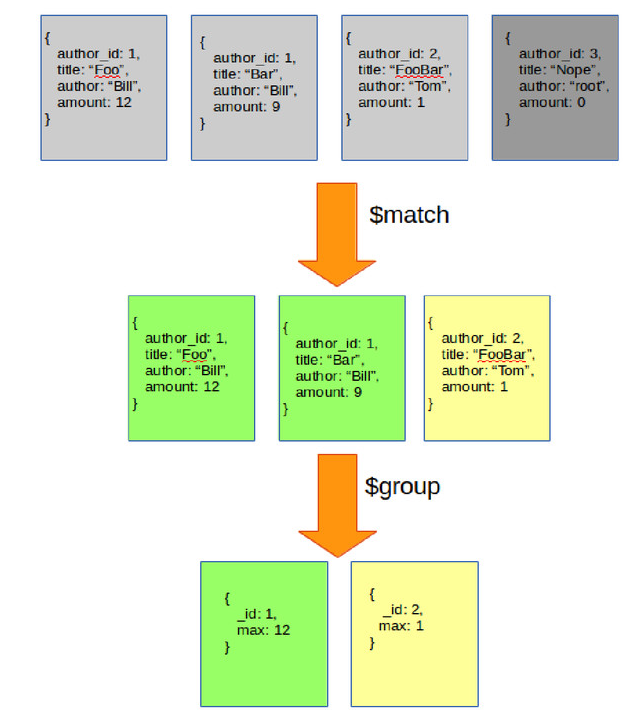
At the end, use sort and limit stages to pick entry with biggest amount.
> db.coding_books.aggregate(
{ $match: { amount: { $gt: 0 } } },
{ $group: { _id: "$author_id", max: { $max: "$amount" } } },
{ $sort: { max: -1 } },
{ $limit: 1 }
)
{
"result" : [
{
"_id" : 1,
"max" : 12
}
],
"ok" : 1
}
Optimization and Limitations
Flexibility of choosing and ordering stages of aggregation pipeline makes it extremely easy to
apply for wide set of tasks. But you should try to move operators that filter data, closely to it start.
That will lead to faster data flow between stages, and finally provides better performance for entire computation.
Indexing fields which are used by $match and $sort also provides boost in performance.
Before MongoDB 2.6 biggest restriction was limit for output(16 Mb).
Aggregation returns Cursor or you could specify collection where output documents will be stored ($out operator), so that limitation no longer exists.
There is limit of memory usage set to 100Mb, for each computation at each stage.
Workaround for memory heavy computations is to set allowDiskUse to true.
Last restriction refers to usage of some specific data types in aggregation stages.