Recently, I started reading Anonymising Health Data and thought about summarising general idea in form of a quick note, let’s try then:

When we deal with sensitive data, we should put some effort in order to protect it. It applies not only to patients health data, but a variety of informations(and products). Users emails, payments transactions etc also shouldn’t leek to the outside world. And even if they leek, or when you decide to publish them, privacy of users/customers should be protected.
There are two main aspects of this issue. One is how to not allow directly connect data with specific person. Second, is how to protected persons from being identified, even without direct pointers (identifiers) to that person (or specific group) in the data.
First problem is relatively easy to deal with, and it’s called as “masking”. You should avoid sharing and storing informations that directly identifies subjects of treatment. Name, insurance number, full physical or IP address are examples of those direct identifiers. If you need to store them in your system, you should set proper access rules to database. Encryption before saving could also be valid option in many cases. If you don’t want to mess your database schema removing some fields, you could introduce randomised values (for instance - fake names). Nevertheless, it’s usually easy to identify and mask those fields. HIPAA provides list of most direct identifiers, gathered in document called “Save Harbor” which lists 18 kinds of data, that could be used for de-identification. But it covers mostly direct identifiers, which are rather obvious.
More challenging is how to deal with indirect identifiers, that could allow de-identification. Even without direct pointers to specific person, identity could be discovered from other informations. For example, only one man in specific town, has five children. Town and number of children don’t look like identifiers but in that case, they are.
But if we find and remove every suspicious case from our dataset, it’s value will drop for research and analytics.
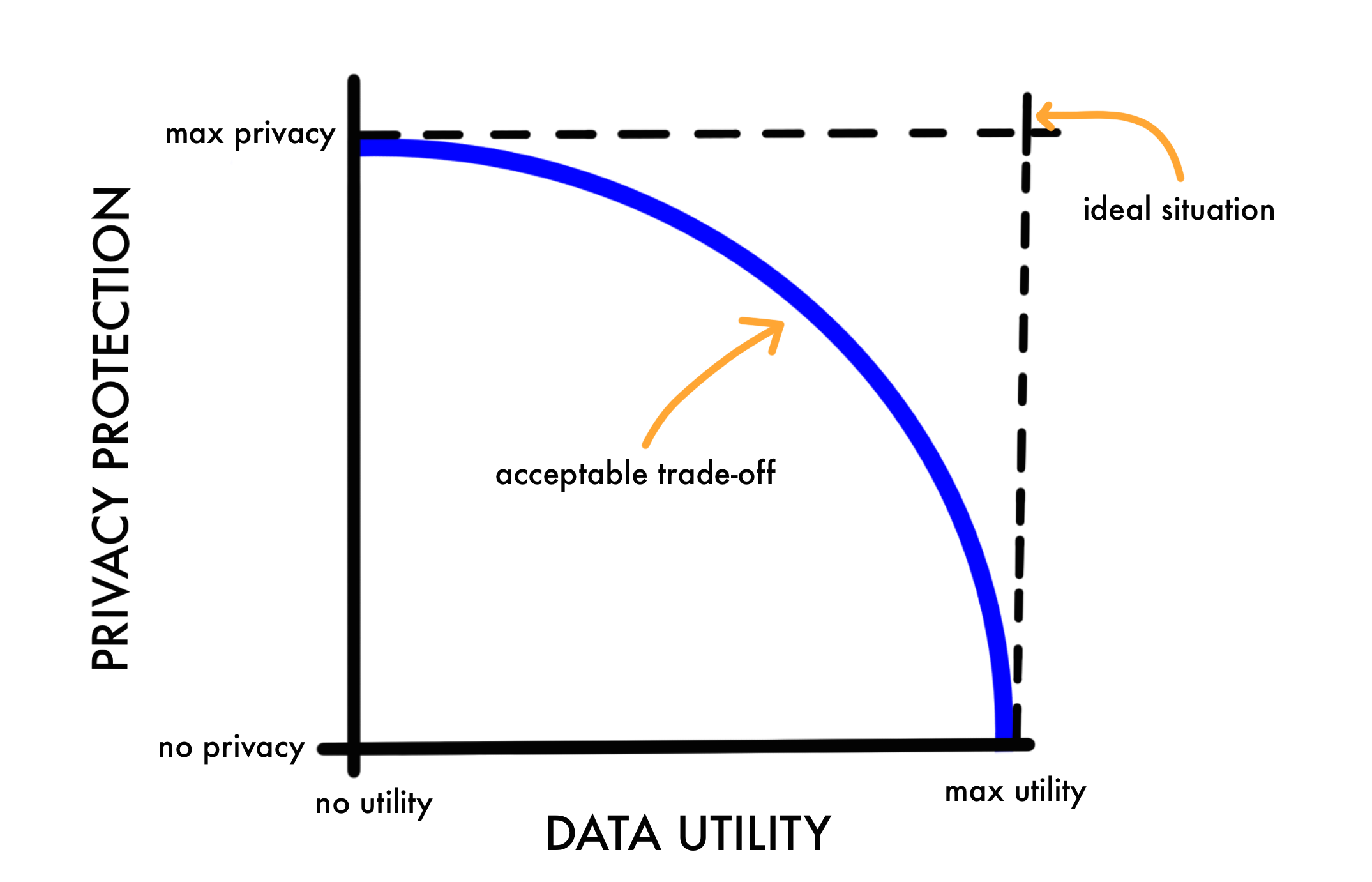
Solution for that, is to find optimal trade-off point between privacy protection and data utility. It requires measuring risk of de-identification on a dataset. After that you could when level of dataset protection is high enough. Removing identifiers is not only way to increase that level, you could also generalise some fields, reducing precision. For example instead of full address, you provide only town, or state. When sharing dataset, you could share only it’s subset, which has lower risk score.
...